AI降噪软件出现,手机双麦克风时代或被终结?
从诺基亚到iPhone X,手机在这些年产生了天翻地覆的变化。按键消失了、边框消失了、连耳机孔都消失了,屏幕越来越大、摄像头也越来越清晰……
不过人们很难感知到的一点变化是,通话中的噪声变得越来越小了。在机场、火车站一类地方嘈杂的背景音中,清晰地听到彼此的声音并不是一件容易的事,麦克风会把环境音一起收集起来,接听时会受到巨大的干扰。
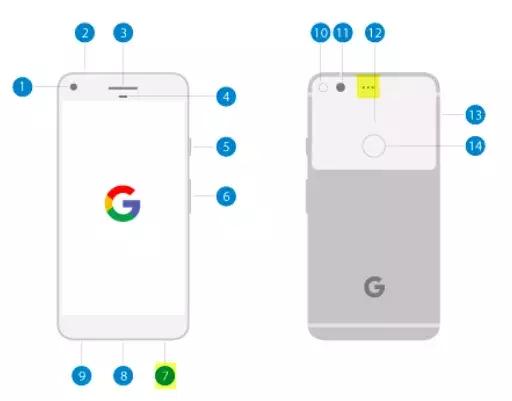
为了解决这个问题,手机厂商做出了很大努力。目前主流的解决方案是双麦克风,一个放在靠近嘴巴的地方收集人声,一个放在顶端或背部收集环境音,再通过算法将人声从背景音中剥离出来,传送到手机的另一端。
但双麦克风+算法真的是主动降噪最好的选择吗?
两个麦克风,仍然解决不了一个老问题
显然不是这样的。
首先双麦克风降噪本身就有一定的局限性,因为算法要在手机终端运行,所以规模不能太大,实现效果也相对有限。具体表现为,有时用户不再说话时,靠近嘴部的麦克风收集的其实还是环境噪音,对于人声剥离的计算会产生一种断断续续的状况。而且当用户使用蓝牙耳机或有线耳机通话时,手机端的双麦克风降噪算法往往又会失效。
同时双麦克风在工业设计上也会造成很多阻碍。两个麦克风会让声学音频路径的设计更加复杂,在ODM和OEM角度都会增加生产设计成本。尤其在如今手机越来越追求屏占比和轻巧的今天,元件自然是越少越好。

而且在一些使用场合中,用来收集人声的麦克风不一定会被放在人们的嘴边。例如在录音,或者应用一些App上的对讲机功能时,人习惯将手机放置在桌子上,或者拿在举例嘴略远地方。这时两个麦克风很难接收到不同的声音,让算法起不到作用。
如果脑洞开的再大一点,未来我们的手机不一定还是如今的平板形状。也许是能卷起来的曲面屏手机,也许是眼镜形态,未来通话的交互方式,也不一定是将手机的一部分放在嘴边收声。
总之,这种双麦克风降噪模式绝不是主动降噪最终的解决方案。
并不新鲜的DNN降噪,怎样才能落实应用?
其实早在2015年,中国科技大学语音与语言信息处理国家工程实验室就创作了关于通过深度神经网络+单麦克风实现主动降噪的论文。具体实现方式是,建立含有噪声+人声和纯净人声的数据集,以深度神经网络为架构训练出分离噪声和人声的“语音增强回归”算法。
在初步试验后,这种算法的结果还不错。从训练成本来看,即使用人工合成的数据,算法结果仍然表现优秀。也就是说算法的应用者不需要面对到现实世界收集数据,可能会侵犯隐私的难题。从应用上来说,这一算法的降噪能力并不比双麦克模式差,甚至还能克服双麦克风克服不不了的间断噪声问题,有时候人们在走路或跑动时接电话会形成偶尔出现的间断噪声,以往的双麦克风模式很难捕捉到这种噪声,但语音增强回归算法就能将人声从中剥离开来。
不过这种算法在这几年间都没有得到很好的应用,原因很简单,深度神经网络模型往往体量较大,很难实现在终端上运行,如果在云端运行,又难免会因为延迟状况不能在实时通话中应用,要知道人类对于交谈时延迟的忍耐最多只有200毫秒。可要是用在语音的后期处理上,好像也并没有什么意义,只要换个收声好一点的话筒就能解决问题,还能保证音质还原。
不过随着这两年以来终端算力的增长,以及对AI算法的不断优化,在终端部署这类模型已经逐渐成为可能。例如一些蓝牙耳机已经部署上了可以在本地运行的RNNoise算法,通过简单的运算来分离单一收音来源的噪声。
除了手机,AI降噪还有更广阔的舞台
这种本地AI降噪技术的应用舞台,不仅仅在手机一种产品上。除了手机通话之外,我们其实无处不受通话噪音的干扰,尤其当语音交互应用的越来也多时,这些问题也越来越严重。
比如在游戏直播时,主播的声音可能会被外放的游戏声音干扰,必须高价购买专用声卡和麦克风才能和粉丝畅快的沟通。又比如车载场景下的语音交互,又有可能被驾车时嘈杂的背景音和导航的声音干扰,最后逼得一些车联网方案将麦克风阵列装置在了方向盘上。以及这几年很流行的智能音箱,为了防止家庭环境中的噪音干扰,需要在麦克风阵列上增加很多成本,像是苹果的HomePod就足足安装了6个麦克风阵列……
但这一切都在被语音增强回归算法和终端计算所改变。
版权保护: 本文由 沃派博客-沃派网 编辑,转载请保留链接: http://www.bdice.cn/html/13336.html


