手把手教你NumPy来实现Word2vec
校对 | 酱番梨 整理 | 菠萝妹
原文链接:
@derekchia/an-implementation-guide-to-word2vec-using-numpy-and-google-sheets-13445eebd281
Word2Vec被认为是自然语言处理(NLP)领域中最大、最新的突破之一。其的概念简单,优雅,(相对)容易掌握。Google一下就会找到一堆关于如何使用诸如Gensim和TensorFlow的库来调用Word2Vec方法的结果。另外,对于那些好奇心强的人,可以查看Tomas Mikolov基于C语言的原始实现。原稿也可以在这里找到。
本文的主要重点是详细介绍Word2Vec。为此,我在Python上使用Numpy(在其他教程的帮助下)实现了Word2Vec,还准备了一个Google Sheet来展示计算结果。以下是代码和Google Sheet的链接。

图1.一步一步来介绍Word2Vec。由代码和Google Sheet呈现
直观上看
Word2Vec的目标是生成带有语义的单词的向量表示,用于进一步的NLP任务。每个单词向量通常有几百个维度,语料库中每个唯一的单词在空间中被分配一个向量。例如,单词“happy”可以表示为4维向量[0.24、0.45、0.11、0.49],“sad”具有向量[0.88、0.78、0.45、0.91]。
这种从单词到向量的转换也被称为单词嵌入(word embedding)。这种转换的原因是机器学习算法可以对数字(在向量中的)而不是单词进行线性代数运算。
为了实现Word2Vec,有两种风格可以选择,Continuous Bag-of-Words(CBOW)或Skip-gram(SG)。简单来说,CBOW尝试从相邻单词(上下文单词)猜测输出(目标单词),而Skip-Gram从目标单词猜测上下文单词。实际上,Word2Vec是基于分布假说,其认为每个单词的上下文都在其附近的单词中。因此,通过查看它的相邻单词我们可以尝试对目标单词进行预测。
根据Mikolov(引用于这篇文章),以下是Skip-gram和CBOW之间的区别:
Skip-gram:能够很好地处理少量的训练数据,而且能够很好地表示不常见的单词或短语
CBOW:比skip-gram训练快几倍,对出现频率高的单词的准确度稍微更好一些
更详细地说,由于Skip-gram学习用给定单词来预测上下文单词,所以万一两个单词(一个出现频率较低,另一个出现频率较高)放在一起,那么当最小化loss值时,两个单词将进行有相同的处理,因为每个单词都将被当作目标单词和上下文单词。与CBOW相比,不常见的单词将只是用于预测目标单词的上下文单词集合的一部分。因此,该模型将给不常现的单词分配一个低概率。
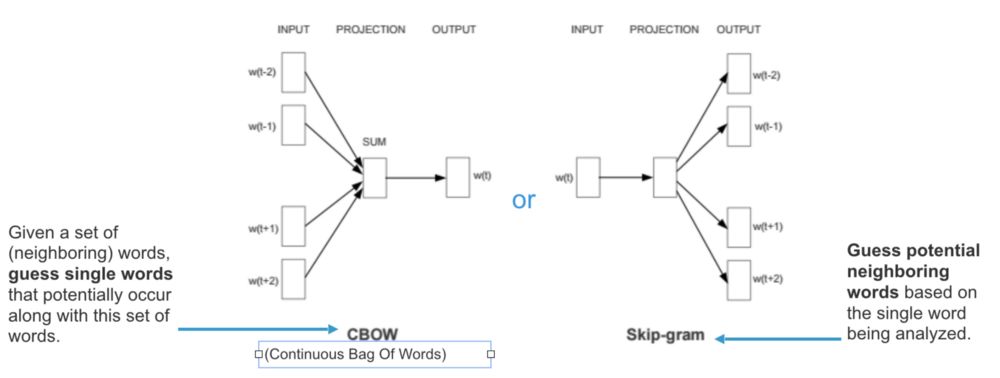
图2—Word2Vec—CBOW和skip-gram模型架构。感谢:IDIL
实现过程
在本文中,我们将实现Skip-gram体系结构。为了便于阅读,内容分为以下几个部分:
1.数据准备——定义语料库、整理、规范化和分词
2.超参数——学习率、训练次数、窗口尺寸、嵌入(embedding)尺寸
3.生成训练数据——建立词汇表,对单词进行one-hot编码,建立将id映射到单词的字典,以及单词映射到id的字典
4.模型训练——通过正向传递编码过的单词,计算错误率,使用反向传播调整权重和计算loss值
5.结论——获取词向量,并找到相似的词
6.进一步的改进 —— 利用Skip-gram负采样(Negative Sampling)和Hierarchical Softmax提高训练速度
1.数据准备
首先,我们从以下语料库开始:
natural language processing and machine learning is fun and exciting
简单起见,我们选择了一个没有标点和大写的橘子。而且,我们没有删除停用词“and”和“is”。
实际上,文本数据是非结构化的,甚至可能很“很不干净”清理它们涉及一些步骤,例如删除停用词、标点符号、将文本转换为小写(实际上取决于你的实际例子)和替换数字等。KDnuggets 上有一篇关于这个步骤很棒的文章。另外,Gensim也提供了执行简单文本预处理的函数——gensim.utils.simple_preprocess,它将文档转换为由小写的词语(Tokens )组成的列表,并忽略太短或过长的词语。
在预处理之后,我们开始对语料库进行分词。我们按照单词间的空格对我们的语料库进行分词,结果得到一个单词列表:
[“natural”, “language”, “processing”, “ and”, “ machine”, “ learning”, “ is”, “ fun”, “and”, “ exciting”]
2.超参数
在进入word2vec的实现之前,让我们先定义一些稍后需要用到的超参数。
版权保护: 本文由 沃派博客-沃派网 编辑,转载请保留链接: http://www.bdice.cn/html/18245.html


