如何减轻软件开发的回测压力?Facebook 已经用上了机器学习
原标题:如何减轻软件开发的回测压力?Facebook 已经用上了机器学习
雷锋网 AI 科技评论按:如何减轻软件开发的回测压力,从而提高工程师的生产效率?MATEUSZ MACHALICA、ALEX SAMYLKIN 等人组成的 Facebook 研究团队提出使用一个利用机器学习的新系统来创建一个为特定代码更改选择回归测试的概率模型,从而更好地执行这种回归测试。
为了高效地开发新产品特征和更新,Facebook 研究团队使用基于主干的开发模型来管理对代码库的改动。一旦一位工程师的代码更改被接入主分支(主干),他们试图让它对从事该产品或服务的其他工程师快速可见。这种基于主干的开发模型比使用特征分支和特征融合更加有效,因为它使得每个人都能够在代码库的最新版本上工作。
但是,在被接受到主干之前,对每项提出的更改进行彻底的回归测试很重要(注:回归测试是指修改了旧代码后, 重新进行测试以确认修改没有引入新的错误或导致其他代码产生错误的一种测试方法)。在从主干被部署到生产之前,每项代码更改都需要经过彻底的回归测试,进入主干异常代码会使得评估新提出的代码更改变得更困难得多,并且还会影响工程师的生产效率。
对此,该研究团队开发了一种更好的方法来执行这项回归测试:使用一个利用机器学习的新系统来创建一个为特定代码更改选择回归测试的概率模型。这种方法需要仅仅运行一个小的测试集,以确保检测到错误的更改。与典型的回归测试选择(RTS)工具不同,该系统通过从历史代码更改和测试结果的大型数据集中学习,来自动开发测试选择策略。
这个预测性测试选择系统已在 Facebook 上部署了一年多,在一段新的代码加入到主干、被其它工程师看到之前,这个系统就可以捕捉超过 99.9% 的回归异常,而且它运行的基于修改的代码的测试数量也只需要以往的三分之一那么多。这也让 Facebook 的基础测试设施的效率得到翻倍的提升。
随着代码库的不断发展,该系统也几乎不要求手动调试。而且经证明,它还能够捕捉产生不一致和不确定性结果的片状测试。
为什么使用创建依赖项是低效的
回归测试的一种常用方法,就是使用从构建元数据中提取的信息来确定在特定代码更改上运行哪些测试。通过分析代码单元间的创建依赖项,可以确定传递依赖于在代码更改中被修正的源的所有测试。例如,在下图中,圆圈表示测试;正方形表示代码的中间单元,如库;菱形表示存储库中的单个源文件。箭头连接起实体 A →B,当且仅当 B 直接依赖于 A 时,他们将其解释为 A 影响 B。蓝色的菱形表示在示例代码更改中被修正的两个文件,所有传递依赖于它们的实体也用蓝色表示。在这个场景中,基于创建依赖项的测试选择策略将执行测试 1,2,3 和 4,但不执行测试 5 和 6,因为后两项测试不依赖于修正的文件。
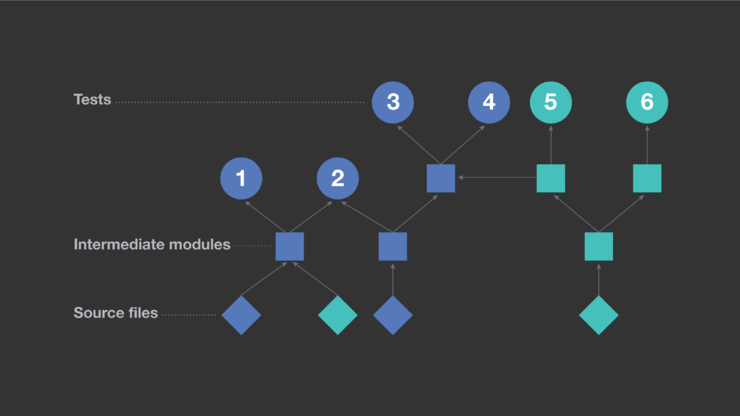
这种方法有一个明显的缺点:它以说「是的,本测试受到影响」告终的次数比实际所需要的要多。平均而言,对于移动代码库的每项更改,该方法都会导致执行多达四分之一的可用测试。如果传递依赖于修正文件的所有测试都真正受到影响,他们将别无选择,而只能将每项测试都执行一遍。然而,在他们的单片代码库中,终端产品依赖于许多可重复使用的组件,这些组件使用一小组低级库。在实践中,许多传递性依赖实际上与回归测试无关。例如,当某个低级库发生更改时,在使用该库的每个项目上重新运行所有测试将是低效的。
软件开发研究领域也开发了其他的回归测试选择方法,例如基于静态更改-影响分析的方法。然而,由于他们代码库的大小和使用的不同编程语言的数量,这些技术在他们的使用案例中是不现实的。
一种新方法:预测性测试选择
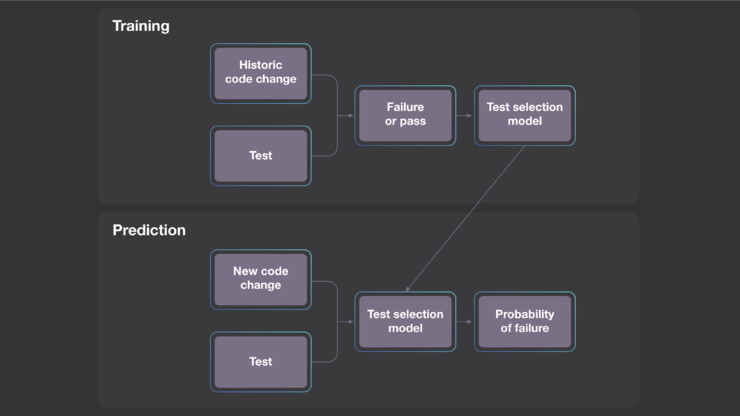
基于创建依赖项的选择测试涉及到判断哪些测试可能受到更改的影响的问题。为了开发更好的方法,Facebook 的研究团队考虑了一个不一样的问题:指定的一项测试发现某个代码修改中的回归问题的可能性有多大?如果他们能估计到这个可能性,就可以做出明智的决定,来排除那些极不可能发现回归的测试。这是对传统测试选择的重大背离,并且开辟了一种新的、更有效的选择测试方法。
作为第一步,该研究团队创建了一个预测模型,该模型针对新提出的代码更改估计每项测试失败的概率。他们通过使用包括历史代码更改上的测试结果在内的大型数据集,然后采用标准的机器学习技术来创建模型,而非手动定义模型。
版权保护: 本文由 沃派博客-沃派网 编辑,转载请保留链接: http://www.bdice.cn/html/19748.html


