史上最强NLP模型GPT 2.0的吃瓜指南

图片来源@视觉中国
文|脑极体
元宵一过 ,年就算正式过完了。没曾想OpenAI和马斯克,居然抓住了春节的小尾巴,携手为全球人民贡献出一个大瓜。
事情是这样的,上周OpenAI推出了一个号称“史上最强通用NLP模型”的新算法GPT-2.0,却没有按照惯例开放该模型和数据集。
研究人员们的溢美之词还没来得及说完,立马被OpenAI这波操作气得怒从心头起,纷纷斥责它全忘初心、恶意炒作。
有人吐槽它应该改名叫“ClosedAI”,还有人把怒火烧到了OPENAI的资助者之一的埃隆·马斯克身上。后者却立马甩锅,表示“没有参与 OpenAI 公司事务已超过一年”,“早就理念不合”,正式发推要求“和平分手”……
不但惹了众怒,还把创始人兼金主爸爸给玩跑了,OpenAI这是摊上大事,顺手承包了一个瓜田啊。
想要有技术、有品位地吃瓜,先得了解一下,能搅乱技术社区的一池春水、让OpenAI心甘情愿背锅的“罪魁祸首”——GPT2.0,到底有什么神奇之处?
风暴中心的GPT2.0究竟有多特别?
我们知道,训练大型神经网络语言模型一直是NLP领域最具含金量的研究。其中,语义的连贯性,也就是语言生成模型预测上下文的准确度,一直是一个“老大难”问题。
为了解决这个难题,性能更好的通用语言模型就成了研究人员关注的重点。从AI2的 ELMo,到OpenAI的GPT1.0,再到前不久Google的BERT,都是为了让机器不再尬言尬语颠三倒四,说话更加通顺连贯。
但万万没想到,几个月前号称“引领NLP走进新时代”的BERT,这么快就被GPT2.0取代了。
按照深度学习四大要素来对比一下,GPT 2.0到底强在哪里呢?
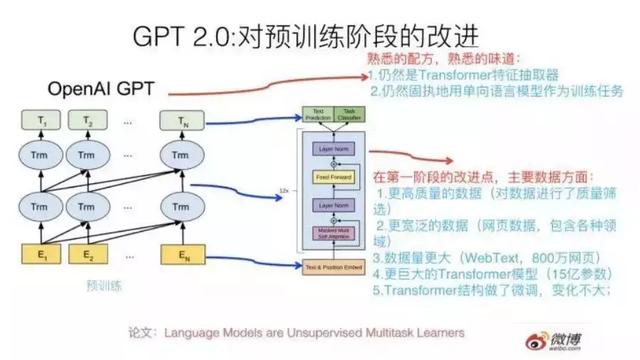
1. 训练数据。引发广泛关注的BERT,使用了3亿参数量进行训练,刷新了11项NLP纪录,这在当时是前所未有的。
而OpenAI推出的GPT-2,则参数量则“丧心病狂”地达到了15亿之多,在一个800 万网页数据集上训练而成,覆盖的主题五花八门。不夸张的说,GPT-2 可能是当前最大的深度模型了。
2. 模型。在深度学习方法上,“先进代表”BERT和GPT-2都采用了Transformer 技术。与传统的特征抽取器RNN、CNN相比,Transformer无论是特征抽取、计算效率,还是翻译任务的综合能力上,都稳操胜券。
不同之处在于,BERT用双向语言模型做预训练,而GPT2.0则使用了古早时代的单向语言模型。坦率地说,GPT-2在预训练中可以使用的架构类型因此受到了限制,无法全面地融合语境,结果就是在下游任务中展现出来的性能远没有当初BERT来得惊艳。
至于为什么不“见贤思齐”,采用更先进的双向语言模型,大概是用长矛干翻步枪这种挑战,更能彰显出“艺高人胆大”的极客风范吧。
3. 算力。“巨无霸”GPT-2的预训练数据量规模横扫所有玩家,使用了约 1000 万篇文章的数据集,文本集合达 40GB。这样训练出来的语言模型优势很明显,比使用专有数据集来的通用性更强,更能理解语言和知识逻辑,可以用于任意领域的下游任务。
但要完成这项任务,必须使用超大规模的GPU机器学习集群,OpenAI为此不得不去争夺紧张而昂贵的GPU训练时间,光是庞大的开销就足以劝退很多想复现其工作的研究者了。
4. 应用。说了这么多,GPT-2的实际应用效果究竟如何呢?来欣赏一下它的文学作品:
输入乔治·奥威尔《一九八四》的开场白:“这是四月的一天,天气晴朗而寒冷,钟敲了十三下”。系统就识别出模糊的未来主义基调和小说风格,并继续写道:
“我在去西雅图找新工作的路上开着车。我把汽油放进去,把钥匙放进去,然后让它跑。我只是想象着那天会是什么样子。一百年后的今天。2045 年,我在中国农村的一所学校教书。我从中国历史和科学史开始。”
不仅情绪模仿到位,GPT-2还能创新观点(哪怕是错误的)。比如发表“回收对世界不利。这对环境有害,对我们的健康有害,对经济不利。”这样毫不政治正确、似是而非的言论。
从实际效果来看,GPT-2理解上下文、生成段落、语序连贯性的能力还是有目共睹的。难怪有专家说,未来加上情节的约束,GPT-2续写《红楼梦》后40回也是有可能的。



版权保护: 本文由 沃派博客-沃派网 编辑,转载请保留链接: http://www.bdice.cn/html/37588.html


