低资源神经机器翻译MetaNMT :来自MAML与NLP的温柔救赎

图片来源@视觉中国
文 | 脑极体
过去十年,随着Attention模型、LSTM、记忆Memory等等方法的出现,尤其是在神经网络的加持下,机器翻译的水平取得了长足的进步。
在英法、中英这样的大语种(Rich Language)翻译任务上,机器的表现几乎可以媲美人类的水平,甚至已经开始登堂入室,承接了不少国际大会的翻译业务,让人类翻译感受到了深深的失业焦虑。
然而,神经机器翻译(NMT)的成功往往依赖于大量高质量的双语语料作为训练数据。如果是蒙古语、印度语这些小语种,无法提供足够多的双语数据,更极端的现实情况是,有些语言几乎没有任何双语预料,这种情况下NMT就无能为力了。
标注数据资源的贫乏问题,一直没有什么好的解决办法。因此,来自香港大学、纽约大学的研究人员Jiatao Gu、Yong Wang等人所提出的新神经机器翻译方法MetaNMT,论文一经发表,就凭借在低资源神经机器翻译(NMT)上的优异性能表现惊艳了学界,成为2018年最具影响力的NLP创新之一。
论文不仅被NLP领域领先的会议EMNLP收录,还拿下了Facebook的低资源神经机器翻译奖。今天,我们就来看看MetaNMT方法究竟有何过人之处?
什么是MetaNMT算法?
简单来说,MetaNMT算法就是将元学习算法(MAML),用于低资源神经机器翻译(NMT)中,将翻译问题建构为元学习问题,从而解决低资源语言语料匮乏的难题。
研究人员先使用许多高资源语言(比如英语和法语),训练出了一个表现极佳的初始参数,然后使构建一个所有语言的词汇表。再以初始参数/模型为基础,训练低资源语言的翻译(比如英语VS希伯来语,法语VS希伯来语)。在此基础上进行进一步优化初始模型,最终得到的模型就可以很好地提升小语种翻译模型的性能。
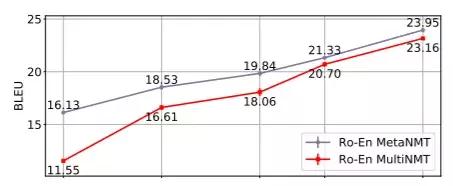
具体到实验中,研究人员使用十八种欧洲语言所训练的元学习策略,被应用在以五种小语种语言(Ro,Lv,Fi,Tr和Ko)为目标的任务中。结果证明,通过16000个翻译单词(约600个并行句子),罗马尼亚语-英语WMT'16上实现高达22.04 BLEU。
数据显示,MetaNMT训练出的系统,表现要明显优于基于多语言迁移学习。这意味着只需要一小部分的训练样例,我们就能训练出效果更好的NMT系统,很多语料库非常小的语言,机器翻译时也不会再一筹莫展或者胡言乱语了。
NLP的神助攻:元学习强在何处?
MetaNMT之所以取得如此良好的效果,核心就在于引入的MAML(Model Agnostic Meta Learning),即与模型无关的元学习方法。
简单来说,元学习就是要让智能体利用以往的知识经验“学会如何学习”(Learning to learn),然后更高效地完成新任务。
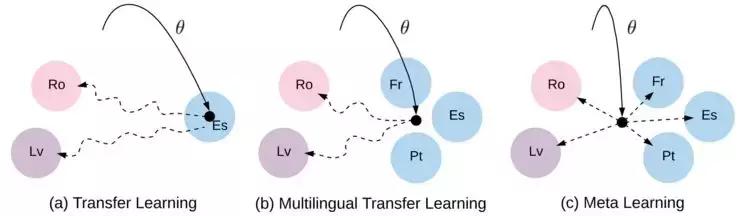
传统NLP任务中常用的迁移学习(transfer leaning)或多任务学习(Multi-Task Learning),输入端训练得到的编码器(Encoder)会直接转化为对应的向量表示序列,直指目标任务。而MetaNMT则是通过高资源语言系统的训练得到一个独立于原任务的通用策略方法,再让极低资源的语言系统根据这种学习方法,并反复地模拟训练。
过去,元学习一直被用来进行小样本学习、通用机器人等训练中,MetaNMT的提出,也是MAML第一次在NLP领域成功应用。那么,未来随着元学习的加入,NLP领域会产生哪些可能的变化呢?
首先,降低NLP任务的研究门槛。
深度增强学习需要的训练数据量规模越来越大,游戏等动态任务环境所涉及的奖励机制也日趋复杂。在StyleGAN、BERT等“巨无霸”模型的争夺下,GPU/TPU计算时长变得极其昂贵,NLP俨然快要成为土豪大公司才有资格玩的游戏了。
与之相比,通过少量样本资源就能学会新概念的元学习方法,可以只使用少量的梯度迭代步来解决新的学习任务,就显得平易近人很多。
其次,提升NLP任务的学习效率。
传统的数据集更新周期长,往往需要根据新任务进行改造和再编辑。而元学习就改变了这一现状。先让系统接触大量的任务进行训练,再从中学会完成新任务的方法,可以快速(只需少量步骤)高效(只使用几个例子)地应用于广泛的NLP任务中。
尤其是在特定领域对话系统、客服系统、多轮问答系统等任务中,在用户的使用过程中就可以收集丰富的信息,让系统在动态学习中构建越来越强大的性能。
除此之外,元学习还能帮助NLP实现个性化、智能化进阶。
版权保护: 本文由 沃派博客-沃派网 编辑,转载请保留链接: http://www.bdice.cn/html/39860.html


