CVPR 2018摘要:第四部分
翻译 | 老赵 校对 | 酱番梨
整理 | 菠萝妹
原文链接:
领域适应的最新进展(CVPR 回顾 -4)
我们已经分三期关于CVPR 2018(计算机视觉和模式识别)会议:第一部分专门讨论计算机视觉的GAN,第二部分涉及关于识别人类(姿势估计和跟踪)的论文,第三部分涉及合成数据。 今天,我们深入探讨最近一直在兴起的深度学习领域的细节:领域适应。 对于这个NeuroNugget,我很高兴为您呈现我的共同作者Anastasia Gaydashenko,他已离开Neuromation并继续加入思科...但他的研究继续存在,这就是其中之一。
什么是领域适应?
最近研究中有几个具体趋势(包括CVPR 2018),其中一个是领域适应。 由于这个领域与合成数据密切相关,因此我们在Neuromation对我们非常感兴趣,但这个主题在本身也越来越受欢迎和重要。
让我们从头开始。 我们已经讨论了构成现代计算机视觉基础的最常见任务:图像分类,对象和姿势检测,实例和语义分割,对象跟踪等。 由于深度卷积神经架构和大量标记数据,这些问题得到了相当成功的解决。
但是,正如我们在上一部分中所讨论的那样,总是存在一个巨大的挑战:对于监督学习,你总是需要找到或创建标记数据集。 几乎所有关于某些奇特的现有技术模型的论文都会提到数据集的一些问题,除非他们使用每个人通常比较的少数标准“ vanilla ”数据集之一。 因此,收集标记数据与设计网络本身一样重要。 这些数据集应该足够可靠和多样化,以便研究人员能够使用它们来开发和评估新颖的架构。
我们已经多次谈到手动数据收集既昂贵又耗时,往往非常耗费精力。 有时甚至不可能手动标记数据(例如,如何标记深度估计,评估图像上的点到相机的距离的问题?)。 当然,许多标准问题已经具有可自由或容易获得的大型标记数据集。 但首先,这些易于标记的数据可以(并且确实)将研究偏向于可用的特定领域,其次,你自己的问题永远不会完全相同,标准数据集通常根本不符合您的要求:它们将包含不同的类别,会有不同的偏置,等等。
使用现有数据集,甚至是没有专门针对你的特定问题的合成数据生成器的主要问题是,当生成数据并且已经标记时,我们仍然面临域转移的问题:我们如何使用一种数据准备网络应对不同种类? 对于整个合成数据领域来说,这个问题也很突出:无论你制作数据是否真实,它仍然无法与现实世界的照片完全区分开来。 这里的主要潜在挑战称为域移位:基本上,目标域中的数据分布(例如,真实图像)与源域中的数据分布(例如,合成图像)不同。 设计能够应对这种转变的模型正是称为域适应的问题。
让我们看看人们现在如何处理这个问题,考虑一下CVPR 2018中的一些论文,比之前的“CVPR in Review”分期付款稍微详细一些。
具有相似性学习的无监督领域适应
Pedro Pinheiro的这项工作(见pdf)来自ElementAI,这是一家蒙特利尔公司,于2016年由Yoshua Bengio共同创立。 它涉及一种基于对抗性网络的域适应方法,我们之前提到的那种方式(参见本文,第二部分即将推出)。
对无监督领域自适应的最简单的对抗方法是尝试提取跨域保持相同的特征的网络。 为了实现这一点,网络试图使它们与网络的单独部分(鉴别器(下图中的“光盘”)无法区分。 但与此同时,这些功能应该代表源域,以便网络能够对对象进行分类:
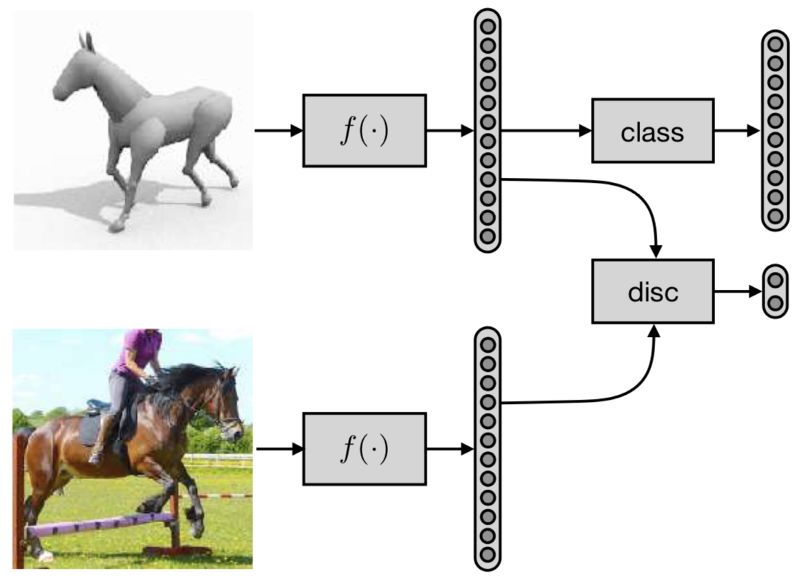
通过这种方式,网络必须提取能够同时实现两个目标的特征:(1)足够的信息,“类”网络(通常非常简单)可以分类,(2)独立于域,以便 “光盘”网络(通常与特征提取器本身一样复杂,或更多)无法真正区分。 请注意,我们不必为目标域提供任何标签,仅针对源域,通常更容易(再次考虑源域的合成数据)。
在Pinheiro的论文中,通过用基于相似性的部分替换分类器部分来改进这种方法。 判别部分保持不变,分类部分现在比较图像与一组原型的嵌入; 所有这些表述都是以端到端的方式共同学习的:
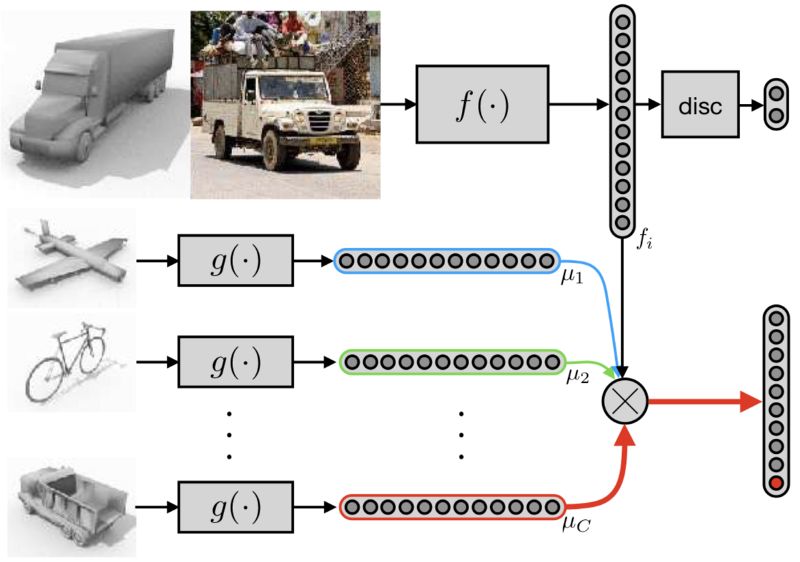
基本上,我们要求一个网络g从标记的源域和另一个网络f中提取特征,以从未标记的目标域中提取具有相似但不同的数据分布的特征。 不同之处在于现在f和g是不同的(我们在上图中有相同的f),并且分类现在是不同的:我们训练模型以区分目标原型和所有其他原型,而不是训练分类器。 为了标记来自目标域的图像,我们将图像的嵌入与来自源域的原型图像的嵌入进行比较,分配其最近邻的标签:
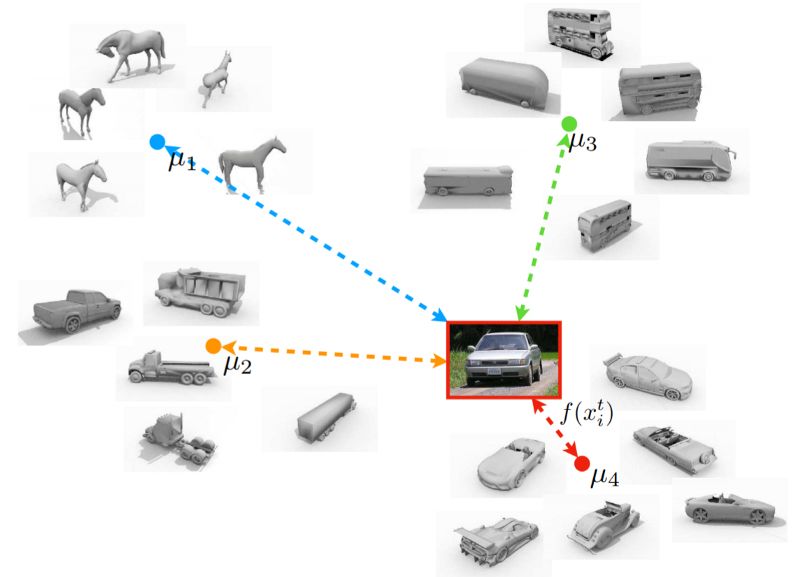
本文表明,所提出的基于相似性的分类方法对于两个数据集之间的域移位更加稳健。
领域适应的图像到图像翻译
版权保护: 本文由 沃派博客-沃派网 编辑,转载请保留链接: http://www.bdice.cn/html/5691.html


