我从这些歌词里,看到了人类复读机的本质

更多科技趣闻,欢迎点击右上角关注我~
也许,你没有刷过抖音,但你有 90% 的概率听过这抖音神曲 ——
“ 我们一起学猫叫,一起喵喵喵喵喵 ”( 接下来的一小时,这段旋律可能会一直在你脑海回荡 )

这首《 学猫叫 》歌曲时长 3 分 29 秒,从头到尾歌词总共 486 个字,其中 “ 一起 ” 出现了 15 次, “ 猫 ” 字出现了 16 次,“ 喵 ” 字使用频率最高,出现了 67 次。。。
如果我们把整首歌里重复的字眼去掉( 只保存首次出现的字 ),差友们猜猜整首歌还剩多少内容?
答案是 101 字。。。
也就是说,这首 3 分多钟的词句创作其实只用到了 100 多个汉字,是不是瞬间有一种作词很容易的错觉?

这种不断重复用词用句的表现方法,在现在的流行音乐创作中似乎变得越来越常见了,甚至形成了一种特殊风格。
我们越来越喜欢听歌词重复的歌曲,这会不会跟现代人日益下降的记忆能力有关呢?
好巧不巧,美国的计算机科学家唐纳德在 1977 年发表了一篇文论《 歌曲的复杂性 》,好好的调侃了一番这个音乐界的世界级现象 —— 流行歌曲的歌词内容重复度越来越高了( 也就是说,他认为每首歌用到的词汇量越来越少 )。。。事情真的是这样的吗?
想要证明这个论点,小辣椒开头用的方法当然不够严谨,而美国一个学者科林 · 莫里斯用 “ 无损数据压缩 ” 的算法,帮唐纳德用大数据论证了一下他的观点。
科林以 1958 年到 2017 年里上过 Billboard 榜单的 15000 首歌作为数据样本,进行了算法分析。
举个例子,洗牙姐( 歌手 Sia )的 Cheap Thrills,整首歌重复循环的段落有很多。
我们把其中重复,看上去没有什么意义的部分全部压缩删除,247 个字节最后只剩下了 133 个,有 46.2% 的词语都是可以被去掉的。。。
压缩过程示意图
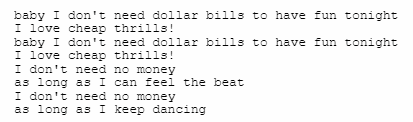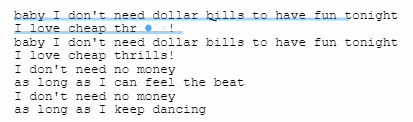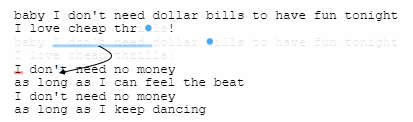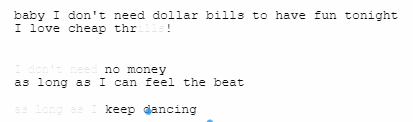
差友们可能也观察到了,有些词语的字母( 比如上面一段中的,thrills,因为 ills 和 bills 重复也被直接压缩了 )也被直接删除了,这是算法的一套删除规则,并不影响最后的统计结果。
不同段落之间的可压缩性也会因为段落的重复度而有所不同。
像是这一段,只有一些词汇而不是整句重复,所以被压缩率就比上一段要低很多。
压缩过程示意图

经过算法一番猛如虎的操作,你猜洗牙姐这首歌的可压缩率有多高?
76% 。。。emmmmm,歌曲里有 76% 的字节都被视为无效信息,可以直接被删除,和替换。
算出结果的科林还皮了一下,自己把 Cheap Thrills 的歌词给改了,意思不变,但是全部有效,无法被算法抹掉。。。
左边为原词,右边是科林的创作

在对样本中的 15000 首歌全部都骚操作了一遍之后,科林得出了这样的一个规律,这些歌曲的平均可压缩性在 50%,也就是至少有一半的歌词重复。。。
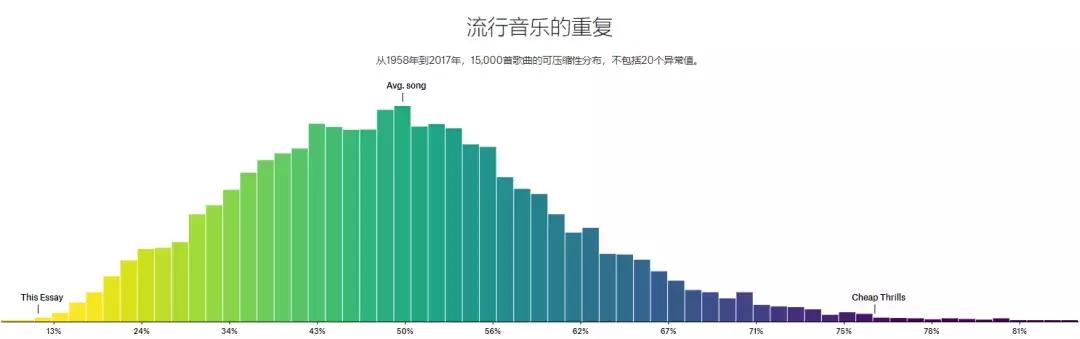
想知道歌词重复率最高的一首是什么歌吗?
是 Daft 在 1997 年创作的电音
整首歌 7 分钟,歌词就只有一句 ——“ Around the world ”。

当然了,你可能会说电音本来就没什么歌词。。。这一点科林也想到了,于是他又排除了 20 首最极端的例子,得到的趋势结果几乎一样。。。
版权保护: 本文由 沃派博客-沃派网 编辑,转载请保留链接: http://www.bdice.cn/html/5817.html


