和 DeepMind 一起考虑如何在 AI 中重现人类的价值观
原标题:和 DeepMind 一起考虑如何在 AI 中重现人类的价值观
雷锋网 AI 科技评论按:现在提到 AI 的时候,大家已经很少联想到电影《终结者》中的天网那样有自己独特思维逻辑以至于得出了反人类结论的「超人类智能」了。这当然是件好事,说明我们都知道了现阶段的 AI 并不具有那样的逻辑思维能力,沿着现有方向继续发展下去也不会有;也说明我们已经了解了身边就有形形色色的运用机器学习解决具体问题的技术成果。
但我们同时也面对着一个新问题,就是随着人类用模型做出越来越多的决策,模型所看重的因素真的和设计它的人类所希望的一样吗?又或者,模型完全捕捉了设计者提供的数据中的模式,但数据本身却含有设计者没有意识到的偏见。这时候我们又要怎么办?
DeepMind 安全团队的这篇文章就对相关问题做出了一些讨论、提出了一些见解。它概述了 DeepMind 近期一篇论文《Scalable agent alignment via reward modeling: a research direction》中提出的研究方向;这篇论文试图为「智能体对齐」问题提供一个研究方向。由此他们提出了一个基于奖励建模的递归式应用的方法,让机器在充分理解用户意图的前提下,再去解决真实世界中的复杂问题。雷锋网 AI 科技评论编译如下。

近些年,强化学习在许多复杂的游戏环境中展现出令人惊叹的实力,从Atari游戏、围棋、象棋到Dota 2和星际争霸II,AI智能体在许多复杂领域的表现正在迅速超越人类。对研究人员来说,游戏是尝试与检验机器学习算法的理想平台,在游戏中,必须动用综合认知能力才能完成任务,跟解决现实世界问题所需的能力并无两样。此外,机器学习研究人员还可以在云上并行运行上千个模拟实验,为学习系统提供源源不断的训练数据。
最关键的一点是,游戏往往都有明确的目标任务,以及反映目标完成进度的打分系统。这个打分系统不但能够为强化学习智能体提供有效的奖励信号,还能使我们迅速获得反馈,从而判断哪个算法和框架的表现最好。
让智能体与人类一致
不过,AI的终极目标是帮助人类应对现实生活中日益复杂的挑战,然而现实生活中没有设置好的奖励机制,这对于人类评价AI的工作表现来说形成了挑战。因此,需要尽快找到一个理想的反馈机制,让AI能够充分理解人类的意图并帮助人类达成目标。换句话说,我们希望用人类的反馈对AI系统进行训练,使其行为能够与我们的意图保持一致。为了达到这个目的,DeepMind的研究人员们定义了一个「智能体对齐」问题如下:
如何创建行为与用户意图保持一致的智能体?
这个对齐问题可以归纳在强化学习的框架中,差异在于智能体是通过交互协议与用户进行交流、了解他们的意图,而非使用传统的数值化的奖励信号。至于交互协议的形式可以有很多种,当中包括演示(模仿学习,如谷歌的模仿学习机器人)、偏好倾向(人类直接评价结果,如 OpenAI和DeepMind的你做我评 )、最优动作、传达奖励函数等。总的来说,智能体对齐问题的解决方案之一,就是创建一个能让机器根据用户意图运作的策略。
DeepMind的论文《Scalable agent alignment via reward modeling: a research direction》中概述了一个正面解决「智能体对齐」问题的研究方向。基于过去在AI安全问题分类和AI安全问题阐述方面所做的工作,DeepMind将描述这些领域至今所取得的进展,从而启发大家得到一个对于智能体对齐问题的解决方案,形成一个善于高效沟通,会从用户反馈中学习,并且能准确预测用户偏好的系统。无论是应对当下相对简单的任务,还是未来日趋复杂、抽象化的、甚至超越人类理解能力的任务,他们希望系统都能胜任有余。
通过奖励建模进行对齐
DeepMind这项研究方向的核心在于奖励建模。他们首先会训练一个包含用户反馈的奖励模型,通过这种方式捕捉用户的真实意图。与此同时,通过强化学习训练一个策略,使奖励模型的奖励效果最大化。换句话说,他们把学习做什么(奖励模型)与学习怎么做(策略)区分了开来。
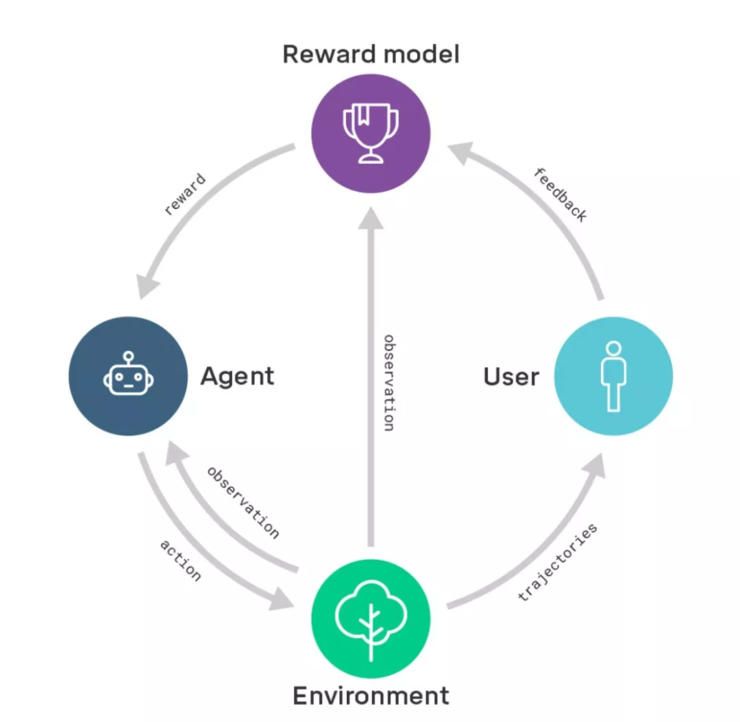
奖励建模示意图:奖励模型基于用户反馈进行训练,以便更好地捕捉用户意图;同一时间,奖励模型为经过强化学习训练的智能体提供奖励。
版权保护: 本文由 沃派博客-沃派网 编辑,转载请保留链接: http://www.bdice.cn/html/6363.html


