深度强化学习从入门到大师:简介篇(第一部分)
翻译 | 斯蒂芬•二狗子、Disillusion
校对 | 斯蒂芬•二狗子 审核 | 就2 整理 | 菠萝妹
原文链接:
深度强化学习从入门到大师:简介篇(第一部分)
您将使用的一些编程环境
本文是深度强化学习课程的一部分,使用 Tensorflow 进行实践。点击这里查看教学大纲。
强化学习是一种重要的机器学习类型,其中智能体通过执行操作和查看结果来了解如何在环境中执行操作。
近年来,我们在这个迷人的研究领域看到了很多改进。例如包括 2014年的DeepMind 的 Deep Q 学习架构,在2016 年 AlphaGo 击败李世石,2017年OpenAI 和 PPO 等。
DeepMind DQN
在本系列文章中,我们将重点学习目前用于解决强化学习问题的不同架构,包括 Q-learning, Deep Q-learning, Policy Gradients, Actor Critic, and PPO.
在这第一篇文章中,您将学到:
什么是强化学习,以及奖励机制是如何成为核心理念的
强化学习的三种方法
深层强化学习的“深层”意味着什么
在深入实现 Deep Reinforcement Learning 智能体之前掌握这些内容非常重要。
强化学习背后的理念是,智能体 Agent 将通过与环境互动并获得执行行动的奖励来学习环境。

从与环境的互动中学习来自人们的自然经验。想象一下,你是一个在起居室里的孩子。你看到一个壁炉,你接近它。
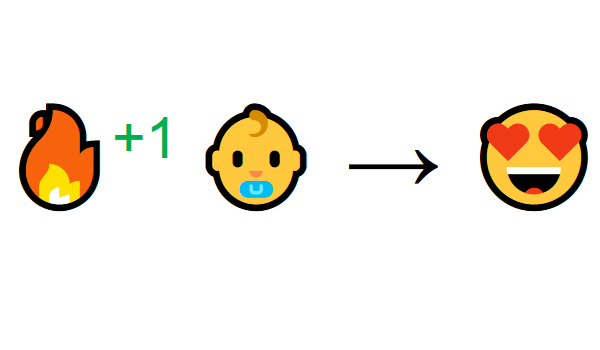
它很温暖,很积极,你感觉很好 (积极奖励+1)。 你感觉火是一件好事。
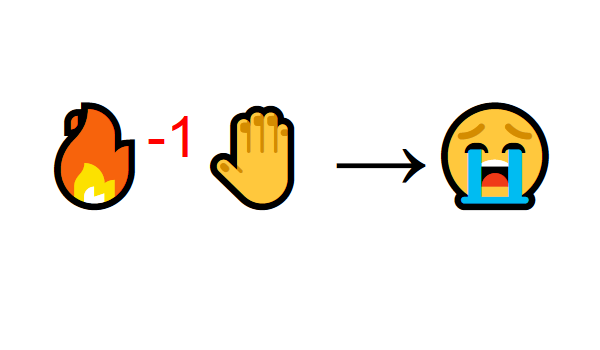
但是你试着触摸火焰。哎哟! 它会烧伤你的手 (负奖励-1)。你已经明白,当你离足够远时火是积极的,因为它会产生温暖。但是太靠近它会烧伤你。
这就是人类通过互动学习的方式。强化学习是一种从行动中学习的计算方法。
强化学习过程

让我看一个智能体学习如何玩超级马里奥的一个例子。强化学习(RL)过程可以建模为一个循环,其具体工作方式如下:
Agent从环境 Environment 获取状态S0(在我们的例子中,从超级马里奥兄弟(环境)接收游戏(状态)的 first frame )
基于该状态S0, 智能体采取行动A0(我们的智能体将向右移动)
环境转换到新状态S1( new frame )
环境给智能体带来一些奖励R1( not dead :+1)
强化学习循环输出state,action和reward的序列,agent的目的是最大化预计累计奖励(expected cumulative reward)
奖励假设函数的核心思想
为什么 Agent 的目标是最大化预期的累积奖励?
实际上,强化学习是基于奖励假设的想法。所有目标都可以通过预期累积奖励的最大化来描述。
这就是为什么在强化学习中,为了获得最佳行为,我们需要最大化预期的累积奖励。
每个时间步t的累积奖励可定义为:
这相当于
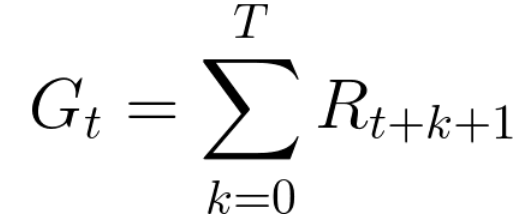
感谢 Pierre-Luc Bacon 的修正
但是,实际上,我们不能光添加这样的奖励。早期(在游戏开始时)提供的奖励更有用,因为它们比未来奖励更好预测。

假设你的 agent 是这只小老鼠而你的对手就是猫。目标是在 agent 被猫吃掉之前吃最多的奶酪。
正如我们在图中可以看到的那样, 老鼠在附近吃奶酪的可能性比接近猫的奶酪更可能( agent 越接近猫,就越危险)。
因此,猫附近的奖励,即使它更大(更多的奶酪),也应该被将打折扣。因为我们不确定 agent 能不能吃到。
为了给奖励打折,可以这样做:
我们定义了一个名为gamma的折扣率。它必须介于0和1之间。
伽玛越大,折扣越小。这意味着学习,agent 更关心长期奖励。
另一方面,伽玛越小,折扣越大。这意味着我们的 agent 更关心短期奖励(最近的奶酪)。
累积的折扣预期奖励是:
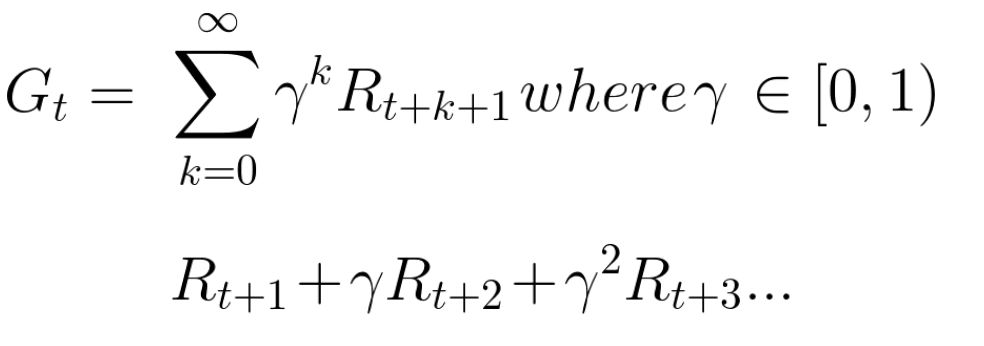
感谢 Pierre-Luc Bacon 的修正
版权保护: 本文由 沃派博客-沃派网 编辑,转载请保留链接: http://www.bdice.cn/html/23368.html


