强化学习的框架化,会引爆AI开发的新脑洞吗?

图片来源@视觉中国
文|脑极体
假如你是应用开发者,不懂算法,又想开发一个带AI功能的APP,你会选择:
自己从头训练一个AI模型;使用开发平台的训练框架和API;
答案显而易见,能够提供技术解决方案及低准入门槛的后者才是王道。
但面对众多开发平台的深度学习框架,需要考虑的问题可就多了:兼容性、社群资源、框架迁移等等不一而足。
而最近,框架之争的焦点又转移到强化学习身上了。
谷歌在去年推出了基于TensorFlow的强化学习框架Dopamine,强化学习界的明星OpenAI也将很多算法放上了baseline,百度也在前不久更新了PaddlePaddle的强化学习框架PARL。就连一向低调的网易,都公布了自主研发的强化编程(Reinforced Programing)框架……
对于大部分开发者来说,强化学习到底能带来什么,与深度学习框架有何区别,自家应用又该何去何从,恐怕还有点云里雾里的。
所以我们今天不妨就来厘清强化学习的真正价值与现实难题。
深度学习、强化学习、深度强化学习,傻傻分不清楚?
经过几年的市场教育,大多数开发者对于深度学习框架能够做什么、怎么做,已经比较有谱了。
但是各大平台随即推出的强化学习框架或者深度强化学习框架,就让人有点蒙圈了。它们之间的区别在哪里,又分别承担着怎样的职责呢?
我们举个例子来解释一下这三种机器学习方法的不同吧:
假如我是个种植工厂,想要做一个能够识别苹果好坏的APP,那么就需要一个深度学习开发框架,在上面搭建训练过程。几乎所有开发平台都有现成的图像识别API,我只需要把训练用的图片(也就是各种各样的苹果照片)拖进系统,就可以得到一个训练好的苹果识别模型了。
但如果我更懒一点,想要一个能自己学会采摘优质成熟苹果的机器人呢?深度学习就有点搞不定了。
这时我需要用强化学习框架来训练一个智能体,每当它摘下一个新鲜漂亮的好苹果,就会收到来自系统的奖励,进行正强化。要是错误摘下了没熟或者烂掉的苹果,就没有奖励甚至会被扣分,进行负强化。
为了得到更多的回报,智能体会就更愿意选择那些好果子来摘,而放弃那些会带来0分甚至负分的果子。通过这种方法,我就得到了一个最大化摘到好果子的智能机器人,岂不是美滋滋?
但尝到甜头的我又不满足了,不仅想让它学会摘黄瓜摘西红柿,而且还懒得再训练一遍。这时候就需要一种全新的算法,将深度学习与强化结合学习起来,只要告诉它新的奖励机制,机器就能通过深度神经网络自主get类似技能,不需要我再手把手训练。
以前,我还需要自己一行行敲代码,现在只要有一个开发框架+训练样本,就可以轻松拥有永不疲倦、勤奋学习、还会举一反三的智能体,这样的诱惑试问谁能拒绝?
当然,这里只是简单解释一下它们的工作模式,真要训练出这样一个智慧模型并应用于自家产品上,是一个更为复杂的综合工程。
不过,增加了强化学习功能的开发框架,大大降低了强化学习训练的编程难度和工作量,对于想做强化学习但又无力从零开始搭建环境和训练的技术人员和企业来说,无疑是个好消息。
AI开发新宠:强化学习究竟有什么用?
如今,强化学习不仅成了学术界的宠儿,相关研究论文在各大顶会中的比例飞速上升;各家开发平台也都把强化学习框架当成重点来部署和争夺。
但问题也随之而来:框架只能降低一部分开发门槛,定制化模型、调试、兼容等工作依然需要企业投入大量人力物力财力,如果费了大力气得到的成果最后无法应用或者不切实际,对开发者来说无疑是非常残酷的。
因此在贸然“以身效法”之前,有必要先搞搞清楚:强化学习到底强在哪些地方?开发者又应该在何种情况下向它投诚?
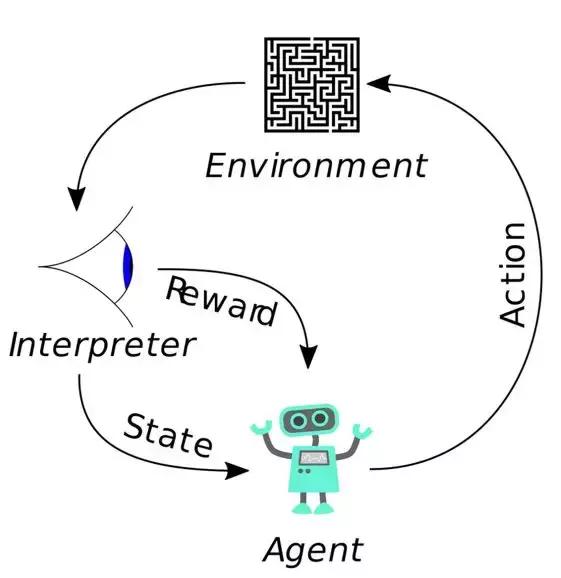
先解释一下强化学习的核心逻辑,那就是智能体(Agent)可以在环境(Environment)中根据奖励(Reward)的不同来判断自己在什么状态(State)下采用什么行动(Action),从而最大限度地提高累积奖励。
比如击败围棋世界冠军的Alpha Go,在《Dota 2》中血虐人类玩家的OpenAI Five,打下Atari 2600游戏最高分的DeepMind DQN,都是基于强化学习实现的。
那么它具体有哪些特征呢,大致可以总结为三个方面:
版权保护: 本文由 沃派博客-沃派网 编辑,转载请保留链接: http://www.bdice.cn/html/30305.html
- 上一篇:社区团购这阵风能刮多久
- 下一篇:九成医疗AI都在做影像,很多熬不过今年


